در توسعهٔ نرمافزار، طراحی اغلب بهعنوان مرحلهای در نظر گرفته میشود که پیش از برنامهنویسی انجام میگیرد. این تصور درست نیست؛ در واقع، تحلیل، برنامهنویسی و طراحی معمولاً با یکدیگر همپوشانی دارند، ترکیب میشوند و در هم میآمیزند. در طول این کتاب، ما ترکیبی از مباحث مربوط به طراحی و برنامهنویسی را پوشش خواهیم داد، بدون آنکه تلاش کنیم آنها را در قالب دستهبندیهای مجزا تفکیک کنیم. یکی از مزیتهای زبانی مانند پایتون این است که امکان بیان طراحی را بهشکلی شفاف فراهم میکند.
در این فصل، کمی دربارهٔ چگونگی حرکت از یک ایدهٔ خوب به سمت نوشتن نرمافزار صحبت خواهیم کرد. ما تعدادی مصنوعات طراحی (design artifacts) ــ مانند نمودارها ــ ایجاد میکنیم که میتوانند پیش از شروع کدنویسی به روشنتر شدن روند تفکرمان کمک کنند. در این فصل به موضوعات زیر خواهیم پرداخت:
همچنین مطالعهٔ موردی (case study) طراحی شیءگرای این کتاب را معرفی خواهیم کرد، که از مدل دیدگاه معماری «4+1» بهره میبرد. در این بخش به چند موضوع دیگر نیز خواهیم پرداخت:
صفحه : [1]
همه میدانند که «شیء» چیست: چیزی ملموس که میتوان آن را حس کرد، لمس کرد و با آن تعامل داشت. نخستین اشیایی که ما با آنها ارتباط برقرار میکنیم معمولاً اسباببازیهای نوزادی هستند. بلوکهای چوبی، اشکال پلاستیکی و قطعات پازل بزرگشده نمونههای رایجی از اولین اشیا هستند. نوزادان بهسرعت یاد میگیرند که برخی اشیا کارهای خاصی انجام میدهند: زنگها به صدا درمیآیند، دکمهها فشرده میشوند و اهرمها کشیده میشوند.
تعریف یک شیء در توسعهٔ نرمافزار چندان متفاوت نیست. اشیای نرمافزاری ممکن است چیزهای ملموسی نباشند که بتوانید آنها را بردارید، حس کنید یا لمس کنید، اما آنها مدلهایی از چیزی هستند که میتوانند کارهایی انجام دهند و کارهایی نیز بر روی آنها انجام شود. بهطور رسمی، یک شیء مجموعهای از دادهها و رفتارهای وابسته به آنهاست.
حال که میدانیم شیء چیست، شیءگرا بودن چه معنایی دارد؟ در واژهنامه، «oriented» به معنای «جهتگیریکرده بهسوی چیزی» است. بنابراین، برنامهنویسی شیءگرا به معنای نوشتن کدی است که بهسوی مدلسازی اشیا جهتگیری دارد. این تنها یکی از تکنیکهای مختلف برای توصیف اعمال یک سیستم پیچیده است. در این رویکرد، یک مجموعه از اشیای در حال تعامل از طریق دادهها و رفتارهایشان توصیف میشوند.
اگر تا به حال تبلیغات یا مطالب پرشور دربارهٔ این موضوع خوانده باشید، احتمالاً با اصطلاحاتی مانند «تحلیل شیءگرا» (Object-Oriented Analysis یا OOA)، «طراحی شیءگرا» (Object-Oriented Design یا OOD)، «تحلیل و طراحی شیءگرا» (OOAD) و «برنامهنویسی شیءگرا» (OOP) روبهرو شدهاید. همهٔ اینها مفاهیمی مرتبط و زیرمجموعهٔ چتر کلی شیءگرایی هستند.
در حقیقت، تحلیل، طراحی و برنامهنویسی همگی مراحلی از توسعهٔ نرمافزار به شمار میروند. هنگامی که آنها را «شیءگرا» مینامیم، صرفاً نوع رویکردی را مشخص میکنیم که در توسعهٔ نرمافزار دنبال میشود.
«تحلیل شیءگرا» (OOA) فرایند بررسی یک مسئله، سیستم یا وظیفهای است که فردی میخواهد آن را به یک نرمافزار کاربردی تبدیل کند و در این فرایند اشیا و تعاملات میان آنها شناسایی میشوند. مرحلهٔ تحلیل کاملاً مربوط به این است که چه کاری باید انجام شود.
خروجی مرحلهٔ تحلیل، توصیفی از سیستم است که اغلب در قالب الزامات (requirements) بیان میشود. اگر بخواهیم مرحلهٔ تحلیل را در یک گام کامل کنیم، در واقع یک وظیفه را ــ مثلاً اینکه: «بهعنوان یک گیاهشناس، من به یک وبسایت نیاز دارم تا به کاربران در ردهبندی گیاهان کمک کند تا بتوانم در شناسایی صحیح یاری برسانم» ــ به مجموعهای از ویژگیهای موردنیاز تبدیل کردهایم.
بهعنوان نمونه، در ادامه چند الزام آورده شده است که نشان میدهد یک بازدیدکنندهٔ وبسایت ممکن است چه کارهایی نیاز داشته باشد. هر مورد یک عمل (action) است که به یک شیء (object) گره خورده است؛ برای برجستهسازی، اعمال را بهصورت ایتالیک و اشیا را بهصورت بولد نوشتهایم:
صفحه : [2]
بهنوعی، اصطلاح «تحلیل» (analysis) نامگذاری چندان دقیقی نیست. نوزادی که پیشتر از او صحبت کردیم، بلوکها و قطعات پازل را تحلیل نمیکند. او محیط اطراف خود را جستوجو میکند، شکلها را دستکاری میکند و میبیند کجاها ممکن است جا بخورند. شاید عبارت مناسبتر «کاوش شیءگرا» (object-oriented exploration) باشد.
در توسعهٔ نرمافزار، مراحل ابتدایی تحلیل شامل مصاحبه با مشتریان، مطالعهٔ فرایندهای آنها و کنار گذاشتن گزینههای نامناسب است.
طراحی شیءگرا (Object-Oriented Design یا OOD) فرایند تبدیل چنین الزامات (requirements) به یک مشخصهٔ پیادهسازی (implementation specification) است. طراح باید اشیا را نامگذاری کند، رفتارها را تعریف کند و بهطور رسمی مشخص کند کدام اشیا میتوانند رفتارهای خاصی را روی سایر اشیا فعال کنند. مرحلهٔ طراحی تماماً دربارهٔ تبدیل آنچه باید انجام شود به چگونه باید انجام شود است.
خروجی مرحلهٔ طراحی، یک مشخصهٔ پیادهسازی است. اگر بخواهیم این مرحله را در یک گام کامل کنیم، در واقع الزامات تعریفشده در مرحلهٔ تحلیل شیءگرا را به مجموعهای از کلاسها و اینترفیسها تبدیل کردهایم که (در حالت ایدئال) در هر زبان برنامهنویسی شیءگرا قابل پیادهسازی باشند.
برنامهنویسی شیءگرا (Object-Oriented Programming یا OOP) فرایند تبدیل طراحی به یک برنامهٔ کاربردی است که همان چیزی را انجام میدهد که صاحب محصول در ابتدا درخواست کرده است.
البته، کاش دنیا به این ایدئال پایبند بود و میتوانستیم این مراحل را یکی پس از دیگری و با ترتیبی کامل، درست همانطور که کتابهای قدیمی آموزش میدادند، دنبال کنیم. اما واقعیت، معمولاً مبهمتر و پیچیدهتر است. فرقی نمیکند چقدر تلاش کنیم این مراحل را جدا از هم نگه داریم، همیشه هنگام طراحی با مواردی روبهرو میشویم که به تحلیل بیشتری نیاز دارند. همچنین، وقتی در حال برنامهنویسی هستیم، به ویژگیهایی برمیخوریم که نیازمند شفافسازی بیشتر در طراحی هستند.
بیشتر شیوههای توسعهٔ نرمافزار در قرن ۲۱ به این نکته پی بردهاند که این زنجیرهٔ آبشاری (waterfall) از مراحل نتیجهٔ چندان خوبی ندارد. آنچه کارآمدتر به نظر میرسد، یک مدل توسعهٔ تکرارشونده (iterative development) است. در توسعهٔ تکرارشونده، بخشی کوچک از وظیفه مدلسازی، طراحی و برنامهنویسی میشود و سپس محصول بازبینی و گسترش مییابد تا هر ویژگی بهبود یابد و ویژگیهای جدید در مجموعهای از چرخههای توسعهٔ کوتاه اضافه شوند.
بخش باقیماندهٔ این کتاب دربارهٔ برنامهنویسی شیءگرا خواهد بود، اما در این فصل ما اصول پایهای شیءگرایی را در زمینهٔ طراحی بررسی میکنیم. این کار به ما اجازه میدهد تا مفاهیم را درک کنیم بدون آنکه مجبور باشیم با قواعد نحوی زبان یا خطاهای اجرای پایتون (tracebacks) درگیر شویم.
صفحه : [3]
یک شیء مجموعهای از دادهها همراه با رفتارهای وابسته به آنهاست. اما چطور میتوانیم بین انواع مختلف اشیا تفاوت قائل شویم؟ سیبها و پرتقالها هر دو شیء هستند، اما ضربالمثل مشهوری هست که میگوید نمیتوان آنها را با هم مقایسه کرد. سیب و پرتقال در برنامهنویسی رایانهای چندان مدلسازی نمیشوند، اما فرض کنیم مشغول ساخت یک برنامهٔ مدیریت موجودی (inventory application) برای یک مزرعهٔ میوه هستیم. برای سادهتر کردن مثال، میتوانیم فرض کنیم که سیبها در بشکهها (barrels) و پرتقالها در سبدها (baskets) قرار میگیرند.
دامنهٔ مسئلهای که تاکنون مشخص کردهایم چهار نوع شیء دارد: سیبها، پرتقالها، سبدها و بشکهها. در مدلسازی شیءگرا، اصطلاحی که برای یک «نوع» شیء به کار میرود، «کلاس» (class) است. بنابراین، به زبان فنی، اکنون چهار کلاس از اشیا داریم.
درک تفاوت میان شیء (object) و کلاس (class) بسیار مهم است. کلاسها، اشیای مرتبط را توصیف میکنند. آنها مانند نقشهها یا قالبهایی هستند برای ایجاد یک شیء. ممکن است سه پرتقال روی میز مقابلتان قرار داشته باشد. هر پرتقال یک شیء مجزا است، اما هر سه دارای ویژگیها (attributes) و رفتارهای (behaviors) مشترک مربوط به یک کلاس هستند: کلاس کلی پرتقالها.
رابطهٔ میان این چهار کلاس شیء در سیستم مدیریت موجودی ما را میتوان با استفاده از یک نمودار کلاسی زبان مدلسازی یکپارچه (Unified Modeling Language یا UML) توصیف کرد. (UML همواره به این نام سهحرفی شناخته میشود، چون به نظر میرسد مخففهای سهحرفی هیچوقت از مُد نمیافتند!) این نخستین نمودار ما خواهد بود.
class diagram:
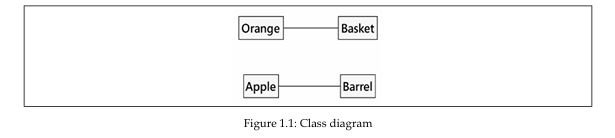
این نمودار نشان میدهد که نمونههای کلاس Orange (که معمولاً «پرتقالها» نامیده میشوند) بهنوعی با یک Basket (سبد) مرتبط هستند و نمونههای کلاس Apple («سیبها») نیز بهنوعی با یک Barrel (بشکه) در ارتباطاند. ارتباط (Association) ابتداییترین روشی است که از طریق آن نمونههای دو کلاس میتوانند به هم مربوط شوند.
نحو (syntax) یک نمودار UML عموماً کاملاً بدیهی است؛ برای اینکه بفهمید (تا حد زیادی) چه چیزی در جریان است، لازم نیست یک آموزش کامل بخوانید. UML همچنین نسبتاً ساده برای ترسیم است و بسیار شهودی به نظر میرسد. در نهایت، بسیاری از افراد هنگام توصیف کلاسها و روابطشان بهطور طبیعی جعبههایی میکشند و بین آنها خطوطی رسم میکنند. داشتن یک استاندارد مبتنی بر این نمودارهای شهودی باعث میشود برنامهنویسان بتوانند بهراحتی با طراحان، مدیران و همچنین یکدیگر ارتباط برقرار کنند.
صفحه : [4]
توجه داشته باشید که نمودار UML معمولاً تعاریف کلاسها را نمایش میدهد، اما ما در حال توصیف ویژگیهای اشیا هستیم. نمودار کلاس Apple و کلاس Barrel را نشان میدهد و به ما میگوید که یک سیب مشخص در یک بشکهٔ خاص قرار دارد. البته میتوانیم از UML برای نمایش اشیای منفرد نیز استفاده کنیم، اما این کار بهندرت لازم میشود. نمایش خودِ کلاسها اطلاعات کافی دربارهٔ اشیای عضو هر کلاس در اختیار ما قرار میدهد.
برخی برنامهنویسان UML را بیهوده میدانند. آنها با استناد به توسعهٔ تکرارشونده (iterative development) استدلال میکنند که مشخصههای رسمی طراحیشده در قالب نمودارهای پرزرقوبرق UML قبل از پیادهسازی منسوخ خواهند شد و نگهداری این نمودارهای رسمی فقط وقت تلف میکند و سودی برای هیچکس ندارد.
با این حال، هر تیم برنامهنویسی که بیش از یک نفر عضو داشته باشد، گاهی مجبور میشود کنار هم بنشیند و جزئیات اجزایی را که ساخته میشوند بررسی و نهایی کند. UML برای ایجاد ارتباط سریع، آسان و سازگار بسیار مفید است. حتی سازمانهایی که نمودارهای رسمی کلاس UML را بیفایده میدانند، معمولاً در جلسات طراحی یا بحثهای تیمی خود از نوعی نسخهٔ غیررسمی UML استفاده میکنند.
علاوه بر این، مهمترین فردی که در آینده باید با او ارتباط برقرار کنید، خودِ آیندهٔ شماست. همهٔ ما فکر میکنیم میتوانیم تصمیمات طراحیمان را به خاطر بسپاریم، اما همیشه لحظاتی پیش خواهد آمد که از خود میپرسیم: «چرا این کار را کردم؟» اگر برگههایی را که در شروع طراحی برای ترسیم نمودارهای اولیه استفاده کردهایم نگه داریم، در آینده متوجه میشویم که آنها به مرجعی بسیار مفید تبدیل شدهاند.
البته این فصل قرار نیست یک آموزش جامع UML باشد. منابع زیادی در اینترنت و همچنین کتابهای متعددی در این زمینه وجود دارند. UML بسیار فراتر از نمودارهای کلاس و شیء است؛ این زبان نحوی برای موارد کاربردی (use cases)، استقرار (deployment)، تغییر وضعیت (state changes) و فعالیتها (activities) نیز دارد. ما در این بحثِ طراحی شیءگرا با برخی از دستورهای رایج نمودار کلاس UML سروکار خواهیم داشت. شما میتوانید ساختار آن را با مثال بیاموزید و سپس ناخودآگاه در یادداشتهای طراحی تیمی یا شخصی خود از نگارشی الهامگرفته از UML استفاده کنید.
نمودار اولیهٔ ما، هرچند درست است، اما یادآور نمیشود که سیبها در بشکهها قرار میگیرند یا اینکه یک سیب در چند بشکه میتواند باشد. تنها چیزی که نشان میدهد این است که سیبها بهنوعی با بشکهها در ارتباطاند. رابطهٔ میان کلاسها اغلب بدیهی است و نیازی به توضیح بیشتر ندارد، اما در صورت لزوم میتوانیم شفافیت بیشتری اضافه کنیم.
زیبایی UML در این است که بیشتر چیزها اختیاریاند. تنها لازم است بهاندازهای اطلاعات در نمودار مشخص کنیم که با وضعیت فعلی سازگار باشد. در یک جلسهٔ سریع روی وایتبورد شاید فقط خطوط سادهای بین جعبهها رسم کنیم، اما در یک سند رسمی ممکن است وارد جزئیات بیشتری شویم.
صفحه : [5]
در مورد سیبها و بشکهها، میتوانیم با اطمینان بگوییم که چندین سیب در یک بشکه قرار میگیرند. اما برای اینکه هیچکس این رابطه را با ضربالمثل «یک سیب فاسد، یک بشکه را خراب میکند» اشتباه نگیرد، میتوانیم نمودار را همانطور که در اینجا نشان داده شده است، کاملتر و شفافتر کنیم:
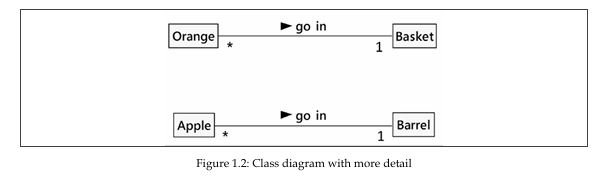
این نمودار به ما نشان میدهد که پرتقالها در سبدها قرار میگیرند، و فلش کوچکی مشخص میکند که چه چیزی در چه چیزی جای میگیرد. همچنین، نمودار تعداد اشیایی را که میتوان در هر سمت رابطه استفاده کرد نمایش میدهد. یک Basket میتواند تعداد زیادی (که با علامت * نشان داده میشود) شیء Orange را در خود جای دهد. در مقابل، هر Orange دقیقاً میتواند در یک Basket قرار بگیرد.
به این عدد، «چندگانگی» (Multiplicity) شیء گفته میشود. ممکن است آن را با اصطلاح «کاردیـنالیتی» (Cardinality) نیز بشنوید. درک تفاوت این دو کمککننده است: کاردینالیتی معمولاً به یک عدد یا بازهٔ مشخص اشاره دارد، در حالی که چندگانگی بیشتر به معنای کلی «بیش از یک نمونه» به کار میرود.
گاهی فراموش میکنیم که کدام سمت خط رابطه باید کدام عدد چندگانگی را داشته باشد. قاعده این است: عدد چندگانگی که نزدیک به یک کلاس نوشته میشود، تعداد اشیای آن کلاس را نشان میدهد که میتوانند با یک شیء در سمت دیگر رابطه در ارتباط باشند.
برای مثال، در رابطهٔ سیب در بشکه قرار میگیرد، اگر از چپ به راست بخوانیم: تعداد زیادی نمونه از کلاس Apple (یعنی اشیای Apple) میتوانند در یک Barrel جای بگیرند. و اگر از راست به چپ بخوانیم: دقیقاً یک Barrel میتواند با هر Apple مرتبط باشد.
اکنون ما با اصول اولیهٔ کلاسها و چگونگی تعیین روابط میان اشیا آشنا شدیم. مرحلهٔ بعدی این است که دربارهٔ ویژگیها (Attributes) که حالت (state) یک شیء را تعریف میکنند و رفتارها (Behaviors) که ممکن است شامل تغییر حالت یا تعامل با سایر اشیا باشند، صحبت کنیم.
اکنون با برخی از اصطلاحات پایهای شیءگرایی آشنا شدهایم. اشیا (Objects) نمونههایی از کلاسها هستند که میتوانند با یکدیگر در ارتباط باشند. یک نمونهٔ کلاس، شیئی خاص با مجموعهٔ دادهها و رفتارهای مخصوص به خود است؛ بهعنوان مثال، یک پرتقال مشخص روی میز جلوی ما یک نمونه (Instance) از کلاس کلی پرتقالها به شمار میآید.
پرتقال دارای حالت (State) است، مثلاً رسیده یا نارس. ما حالت یک شیء را از طریق مقادیر ویژگیهای خاص (Attributes) آن پیادهسازی میکنیم. پرتقال همچنین دارای رفتارها (Behaviors) است. البته، پرتقالها بهخودیِ خود معمولاً منفعلاند؛ تغییر حالتها از بیرون بر آنها تحمیل میشوند.
بیایید دقیقتر به معنای این دو واژه بپردازیم: حالت (State) و رفتارها (Behaviors).
صفحه : [6]
بیایید با دادهها شروع کنیم. دادهها ویژگیهای فردی یک شیء خاص را نمایش میدهند؛ همان حالت کنونی آن شیء. یک کلاس میتواند مجموعهای مشخص از ویژگیها (characteristics) را تعریف کند که در همهٔ اشیای عضو آن کلاس وجود دارند. هر شیء خاص، مقادیر متفاوتی برای این ویژگیها خواهد داشت.
برای مثال، سه پرتقال روی میز (اگر هنوز هیچکدام را نخورده باشیم) ممکن است هرکدام وزن متفاوتی داشته باشند. کلاس پرتقال میتواند یک ویژگی به نام weight (وزن) داشته باشد تا این داده را نمایش دهد. تمام نمونههای کلاس پرتقال ویژگی وزن را خواهند داشت، اما مقدار این ویژگی در هر پرتقال میتواند متفاوت باشد. البته ویژگیها لزوماً منحصربهفرد نیستند؛ دو پرتقال میتوانند وزن یکسانی داشته باشند.
ویژگیها اغلب با اصطلاحات member یا property نیز شناخته میشوند. برخی نویسندگان بین این دو تفاوت قائل میشوند؛ معمولاً به این شکل که attribute قابل تنظیم است، در حالی که property فقط خواندنی (read-only) است. در پایتون میتوان یک property را فقط خواندنی تعریف کرد، اما مقدار آن در نهایت بر پایهٔ مقادیری از attributeهایی است که قابل نوشتن هستند. بنابراین، مفهوم «فقط خواندنی» بودن چندان معنای عملی ندارد. در سراسر این کتاب، ما این دو اصطلاح را بهطور مترادف به کار خواهیم برد.
علاوه بر این، همانطور که در فصل پنجم (زمان استفاده از برنامهنویسی شیءگرا) خواهیم دید، کلیدواژهٔ property در پایتون معنای خاصی برای نوعی ویژگی دارد.
در پایتون میتوانیم به یک attribute «متغیر نمونه» (instance variable) نیز بگوییم. این نامگذاری کمک میکند بهتر بفهمیم ویژگیها چگونه کار میکنند. آنها متغیرهایی با مقادیر منحصربهفرد برای هر نمونه از یک کلاس هستند. البته پایتون انواع دیگری از attributeها هم دارد، اما ما در اینجا روی رایجترین نوع تمرکز میکنیم.
در برنامهٔ مدیریت موجودی میوهٔ ما، کشاورز ممکن است بخواهد بداند هر پرتقال از کدام باغ آمده، چه زمانی چیده شده و چه وزنی دارد. همچنین ممکن است بخواهد پیگیری کند که هر Basket کجا ذخیره شده است. سیبها میتوانند یک ویژگی color (رنگ) داشته باشند، و بشکهها نیز ممکن است در اندازههای مختلف موجود باشند.
برخی از این ویژگیها ممکن است متعلق به چند کلاس مختلف باشند (مثلاً ممکن است بخواهیم زمان چیدهشدن سیبها را هم بدانیم)، اما در این مثال نخست، صرفاً چند ویژگی مختلف به نمودار کلاسی خود اضافه میکنیم:
صفحه [7]
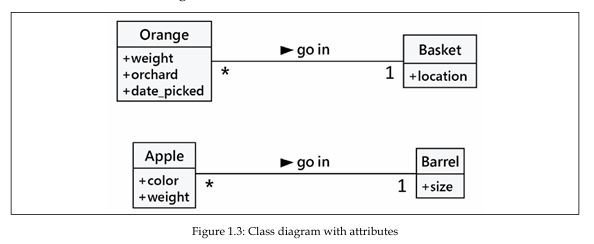
بسته به اینکه طراحی ما تا چه حد نیاز به جزئیات داشته باشد، میتوانیم نوع (type) مقدار هر ویژگی را نیز مشخص کنیم. در UML، انواع ویژگیها اغلب نامهای عمومی و رایجی هستند که در بسیاری از زبانهای برنامهنویسی دیده میشوند، مانند: عدد صحیح (integer)، عدد اعشاری (floating-point number)، رشته (string)، بایت (byte) یا بولی (Boolean). با این حال، آنها میتوانند مجموعههای عمومیتری مانند فهرستها (lists)، درختها (trees) یا گرافها (graphs) را نیز نشان دهند؛ یا مهمتر از همه، کلاسهای خاصِ برنامه (application-specific classes) که غیرعمومی هستند.
این بخش یکی از جاهایی است که مرحلهٔ طراحی میتواند با مرحلهٔ برنامهنویسی همپوشانی پیدا کند. انواع دادههای اولیه (primitive types) و مجموعههای از پیشساختهٔ در دسترس در یک زبان برنامهنویسی ممکن است با آنچه در زبانی دیگر وجود دارد متفاوت باشد.
در ادامه، نسخهای از نمودار را میبینیم که (عمدتاً) از راهنمای نوعدهی پایتون (Python-specific type hints) استفاده کرده است:
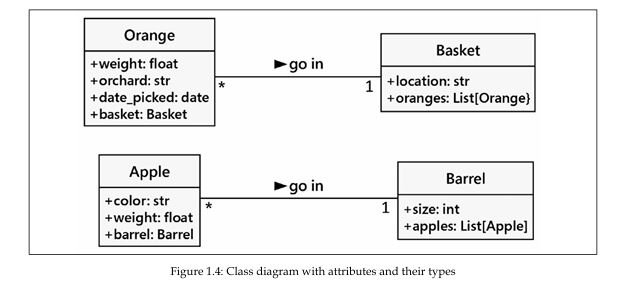
صفحه [8]
معمولاً در مرحلهٔ طراحی لازم نیست بیش از حد نگران انواع داده باشیم، زیرا جزئیات وابسته به پیادهسازی در مرحلهٔ برنامهنویسی انتخاب میشوند. نامهای عمومی معمولاً برای طراحی کافی هستند؛ به همین دلیل ما از date بهعنوان یک نام جایگزین (placeholder) برای نوعی در پایتون مانند datetime.datetime استفاده کردیم. اگر طراحی ما به یک نوع ظرف (container type) از جنس فهرست نیاز داشته باشد، برنامهنویسان جاوا میتوانند هنگام پیادهسازی از LinkedList یا ArrayList استفاده کنند، در حالی که برنامهنویسان پایتون (یعنی ما!) ممکن است از راهنمای نوعدهی List[Apple] استفاده کنند و در پیادهسازی واقعی از نوع list بهره ببرند.
در مثال کشاورزی میوهای ما تا اینجا، ویژگیها همگی از نوع دادههای پایه (primitive) هستند. با این حال، برخی ویژگیهای ضمنی (implicit) وجود دارند که میتوانیم آنها را صریح (explicit) کنیم؛ منظور همان ارتباطها (associations) است.
برای یک پرتقال مشخص، ما یک ویژگی داریم که به سبدی اشاره میکند که آن پرتقال را نگه میدارد؛ این ویژگی basket نامیده میشود و نوع آن با راهنمای نوعدهی Basket مشخص میگردد.
اکنون که دانستیم دادهها حالت یک شیء را تعریف میکنند، آخرین اصطلاحی که باید بررسی کنیم رفتارها (Behaviors) است. رفتارها کنشهایی هستند که میتوانند روی یک شیء رخ دهند. رفتارهایی که میتوان روی یک کلاس خاص از اشیا انجام داد، بهصورت متدهای (methods) آن کلاس بیان میشوند.
در سطح برنامهنویسی، متدها شبیه توابع در برنامهنویسی ساختیافته هستند، با این تفاوت که آنها به ویژگیها (attributes) ــ بهویژه متغیرهای نمونه (instance variables) که دادههای مرتبط با آن شیء را در خود دارند ــ دسترسی دارند. درست مانند توابع، متدها میتوانند پارامتر دریافت کنند و مقدار بازگشتی (return value) داشته باشند.
پارامترهای یک متد بهصورت مجموعهای از اشیا به آن داده میشوند که لازم است در طول اجرای متد وارد شوند. نمونههای واقعی اشیایی که هنگام فراخوانی یک متد به آن داده میشوند، معمولاً آرگومانها (arguments) نامیده میشوند. این اشیا در بدنهٔ متد به متغیرهای پارامتر متصل میشوند و توسط متد برای انجام رفتاری که به آن اختصاص داده شده استفاده میگردند. مقادیر بازگشتی نتیجهٔ آن رفتار هستند. تغییرات داخلی در حالت شیء نیز یکی دیگر از نتایج احتمالی اجرای یک متد است.
ما مثال «سیبها و پرتقالها» را تا اینجا به یک برنامهٔ مدیریت موجودی ابتدایی (هرچند کمی اغراقآمیز) کشاندیم. بیایید کمی بیشتر آن را گسترش دهیم و ببینیم آیا هنوز منطقی باقی میماند یا خیر. یکی از کنشهایی که میتواند با پرتقالها مرتبط باشد، عمل چیدن (pick) است. اگر به پیادهسازی فکر کنیم، متد pick باید دو کار انجام دهد:
پس متد pick باید بداند که با کدام سبد سروکار دارد. این کار را با دادن یک پارامتر Basket به متد pick انجام میدهیم.
از آنجا که کشاورز ما همچنین آبمیوه هم میفروشد، میتوانیم به کلاس Orange یک متد دیگر به نام squeeze اضافه کنیم. هنگام فراخوانی، متد squeeze ممکن است مقدار آب پرتقال گرفتهشده را برگرداند و همزمان پرتقال را از Basketای که در آن قرار داشت، حذف کند.
صفحه [9]
کلاس Basket میتواند یک کنش به نام sell داشته باشد. وقتی یک سبد فروخته میشود، سیستم مدیریت موجودی ما ممکن است برخی دادهها را روی اشیایی که هنوز مشخص نشدهاند (برای محاسبات حسابداری و سود) بهروزرسانی کند.
از سوی دیگر، ممکن است سبد پرتقالها پیش از آنکه بتوانیم آن را بفروشیم، فاسد شود؛ در این حالت، یک متد به نام discard اضافه میکنیم.
بیایید این متدها را به نمودار خود اضافه کنیم :
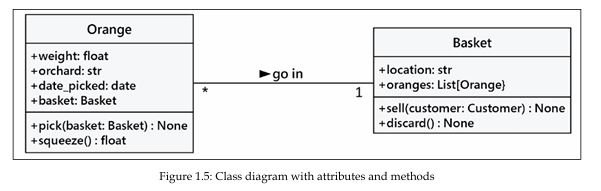
افزودن ویژگیها (attributes) و متدها (methods) به اشیای منفرد به ما امکان میدهد سیستمی از اشیای در حال تعامل بسازیم. هر شیء در سیستم عضوی از یک کلاس مشخص است. این کلاسها تعیین میکنند چه نوع دادهای را میتوان در آن شیء نگه داشت و چه متدهایی را میتوان روی آن فراخوانی کرد. دادههای موجود در هر شیء میتوانند حالتی متفاوت با سایر نمونههای همان کلاس داشته باشند؛ بنابراین هر شیء ممکن است به فراخوانی متدها واکنش متفاوتی نشان دهد، زیرا حالت (state) آن با دیگر نمونهها فرق دارد.
تحلیل و طراحی شیءگرا تماماً مربوط به این است که مشخص کنیم آن اشیا چه هستند و چگونه باید با یکدیگر تعامل داشته باشند. هر کلاس دارای مسئولیتها (responsibilities) و **همکاریها (collaborations)**ی است. بخش بعدی اصولی را توضیح میدهد که میتوان از آنها برای سادهتر و شهودیتر کردن این تعاملات استفاده کرد.
توجه داشته باشید که فروش یک سبد الزاماً ویژگی ذاتی کلاس Basket نیست. ممکن است کلاس دیگری (که در اینجا نشان داده نشده) مسئول پیگیری انواع سبدها و محل آنها باشد. اغلب در طراحی مرزهایی وجود دارد که باید به آنها توجه کنیم. همچنین پرسشهایی دربارهٔ تخصیص مسئولیتها به کلاسهای مختلف پیش خواهد آمد. مسئلهٔ تخصیص مسئولیت همیشه راهحلی کاملاً فنی و منظم ندارد؛ همین امر ما را وادار میکند که بارها نمودارهای UML خود را ترسیم و بازطراحی کنیم تا طرحهای جایگزین را بررسی کنیم.
هدف اصلی از مدلسازی یک شیء در طراحی شیءگرا این است که مشخص کنیم رابط عمومی (public interface) آن شیء چه خواهد بود. رابط عمومی مجموعهای از ویژگیها (attributes) و متدها (methods) است که اشیای دیگر میتوانند برای تعامل با آن شیء به آنها دسترسی داشته باشند.
اشیای دیگر نیازی ندارند ــ و در برخی زبانها حتی اجازه ندارند ــ به جزئیات درونی و نحوهٔ پیادهسازی داخلی شیء دسترسی پیدا کنند.
صفحه [10]
یک نمونهٔ رایج در دنیای واقعی تلویزیون است. رابط ما با تلویزیون کنترل از راه دور است. هر دکمه روی کنترل در واقع نمایانگر یک متد است که میتواند روی شیء تلویزیون فراخوانی شود. هنگامی که ما ــ بهعنوان شیء فراخواننده ــ به این متدها دسترسی پیدا میکنیم، نه میدانیم و نه اهمیتی میدهیم که تلویزیون سیگنال خود را از کابل، دیش ماهواره یا یک دستگاه متصل به اینترنت دریافت میکند. ما توجهی نداریم که چه سیگنالهای الکترونیکی برای تنظیم صدا ارسال میشوند، یا اینکه صدا برای بلندگوها پخش خواهد شد یا برای هدفون. اگر تلویزیون را باز کنیم و به اجزای داخلی آن دسترسی یابیم ــ مثلاً برای اینکه خروجی صدا را هم به بلندگوهای خارجی و هم به هدفون متصل کنیم ــ ممکن است گارانتی دستگاه باطل شود.
این فرایندِ پنهانسازی نحوهٔ پیادهسازی داخلی یک شیء بهدرستی پنهانسازی اطلاعات (information hiding) نامیده میشود. گاهی به آن کپسولهسازی (encapsulation) نیز گفته میشود، اما کپسولهسازی اصطلاحی فراگیرتر است. دادههای کپسولهشده لزوماً پنهان نیستند. Encapsulation بهمعنای واقعی کلمه یعنی ایجاد یک کپسول (یا پوسته) برای ویژگیها و رفتارها. قاب بیرونی تلویزیون حالت و رفتار آن را کپسوله میکند. ما به صفحهنمایش، بلندگوها و کنترل از راه دور دسترسی داریم، اما دسترسی مستقیمی به سیمکشی تقویتکنندهها یا گیرندههای داخل قاب تلویزیون نداریم.
وقتی یک سیستم سرگرمی چندبخشی (component entertainment system) خریداری میکنیم، سطح کپسولهسازی تغییر میکند و بخشی از رابطها میان اجزا آشکار میشود. اگر یک سازندهٔ دستگاههای اینترنت اشیا (IoT maker) باشیم، ممکن است این کپسولهسازی را حتی بیشتر بشکنیم، قابها را باز کنیم و پنهانسازی اطلاعاتی که سازنده در نظر گرفته بود را از بین ببریم.
با این حال، تفاوت بین کپسولهسازی و پنهانسازی اطلاعات تا حد زیادی بیاهمیت است، بهویژه در سطح طراحی. بسیاری از منابع عملی این دو اصطلاح را بهصورت مترادف به کار میبرند. بهعنوان برنامهنویسان پایتون، ما در واقع متغیرهای کاملاً خصوصی و غیرقابلدسترسی نداریم و نیازی هم به آنها نداریم (دربارهٔ دلایل این موضوع در فصل دوم، اشیا در پایتون، بحث خواهیم کرد)، بنابراین تعریف فراگیرتر کپسولهسازی برای ما مناسبتر است.
اما رابط عمومی (public interface) بسیار مهم است. باید با دقت طراحی شود، زیرا تغییر دادن آن وقتی کلاسهای دیگر به آن وابسته باشند، دشوار خواهد بود. تغییر رابط میتواند هر شیء مشتری (client object)ای را که به آن وابسته است از کار بیندازد. ما میتوانیم بخشهای داخلی را هرقدر که بخواهیم تغییر دهیم ــ مثلاً برای بهینهتر کردن یا برای دسترسی به دادهها از طریق شبکه علاوه بر دسترسی محلی ــ و اشیای مشتری همچنان میتوانند بدون تغییر، از طریق رابط عمومی با آن کار کنند.
اما اگر رابط را تغییر دهیم، مثلاً با تغییر نام ویژگیهایی که بهطور عمومی در دسترس هستند یا تغییر ترتیب یا نوع آرگومانهایی که یک متد میتواند بپذیرد، تمام کلاسهای مشتری نیز باید تغییر کنند. بنابراین هنگام طراحی رابطهای عمومی، آن را ساده نگه دارید. همیشه رابط یک شیء را بر اساس سهولت استفاده طراحی کنید، نه بر اساس دشواری پیادهسازی (این توصیه برای رابطهای کاربری یا UI هم صدق میکند).
به همین دلیل، گاهی در پایتون متغیرهایی میبینید که نامشان با یک خط زیرین (_) آغاز میشود؛ این نشانهای است برای هشدار که آن متغیرها بخشی از رابط عمومی نیستند.
صفحه [11]
به یاد داشته باشید، اشیای یک برنامه ممکن است نمایانگر اشیای واقعی باشند، اما این موضوع آنها را به اشیای واقعی تبدیل نمیکند. آنها مدل هستند. یکی از بزرگترین مزایای مدلسازی، توانایی نادیده گرفتن جزئیات بیربط است. مثلاً یکی از نویسندگان وقتی کودک بود، یک ماکت از خودرو Thunderbird 1956 ساخته بود که از بیرون شبیه خودروی واقعی به نظر میرسید، اما بدیهی است که کار نمیکرد. در سنی که هنوز نمیتوانست رانندگی کند، چنین جزئیاتی بیش از حد پیچیده و بیربط بودند. آن ماکت یک انتزاع (abstraction) از یک مفهوم واقعی بود.
انتزاع (Abstraction) یکی دیگر از اصطلاحات شیءگرایی است که با کپسولهسازی (Encapsulation) و پنهانسازی اطلاعات (Information Hiding) ارتباط دارد. انتزاع به معنای کار کردن در سطحی از جزئیات است که برای یک وظیفهٔ خاص مناسبتر است. این فرایند همان استخراج یک رابط عمومی از جزئیات درونی است.
رانندهٔ یک خودرو تنها لازم است با فرمان، پدال گاز و ترمزها تعامل داشته باشد. اما جزئیات مربوط به موتور، سیستم انتقال قدرت یا زیرسیستم ترمز برای او اهمیتی ندارد. در مقابل، یک مکانیک در سطحی متفاوت از انتزاع کار میکند؛ او موتور را تنظیم میکند و ترمزها را هواگیری میکند.
در اینجا مثالی از دو سطح انتزاع برای یک خودرو آورده شده است:
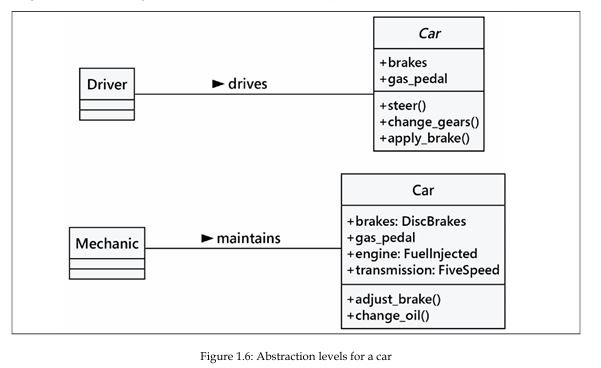
اکنون چند اصطلاح جدید داریم که همگی به مفاهیمی مشابه اشاره میکنند. بیایید این اصطلاحات را در چند جمله خلاصه کنیم:
انتزاع (Abstraction) فرایند کپسولهسازی اطلاعات همراه با یک رابط عمومی جداگانه است. هر عنصر خصوصی میتواند مشمول پنهانسازی اطلاعات (Information Hiding) شود. در نمودارهای UML، معمول است که بهجای علامت + در ابتدای یک ویژگی یا متد (که نشاندهندهٔ عمومی بودن است)، از علامت – استفاده کنیم تا مشخص شود که بخشی از رابط عمومی نیست.
درس مهمی که باید از تمام این تعاریف بگیریم این است که مدلهای ما باید برای اشیای دیگری که قرار است با آنها تعامل داشته باشند قابلفهم باشند. این یعنی توجه دقیق به جزئیات کوچک.
صفحه [12]
اطمینان حاصل کنید که متدها و ویژگیها نامهای معقول و مناسبی داشته باشند. هنگام تحلیل یک سیستم، اشیا معمولاً نمایانگر اسمها (nouns) در مسئلهٔ اصلی هستند، در حالی که متدها غالباً فعلها (verbs) هستند. ویژگیها (attributes) ممکن است بهصورت صفتها (adjectives) یا اسمهای اضافی ظاهر شوند. بنابراین، کلاسها، ویژگیها و متدهای خود را متناسب با این قاعده نامگذاری کنید.
هنگام طراحی رابط، تصور کنید که شما خودِ شیء هستید؛ شما نیازمند تعاریف روشن از مسئولیتهای خود هستید و برای انجام آنها ترجیح قوی به حفظ حریم خصوصی دارید. اجازه ندهید اشیای دیگر به دادههای شما دسترسی داشته باشند، مگر اینکه واقعاً به نفع شما باشد. همچنین رابطی در اختیارشان قرار ندهید که شما را وادار به انجام وظیفهای خاص کند، مگر آنکه مطمئن باشید این وظیفه واقعاً بر عهدهٔ شماست.
تا اینجا یاد گرفتیم که سیستمها را بهصورت مجموعهای از اشیای در حال تعامل طراحی کنیم، جایی که هر تعامل شامل مشاهدهٔ اشیا در سطحی مناسب از انتزاع است. اما هنوز نمیدانیم چگونه این سطوح انتزاع را ایجاد کنیم. روشهای مختلفی برای این کار وجود دارد؛ در فصلهای ۱۰، ۱۱ و ۱۲ به برخی از الگوهای طراحی پیشرفته خواهیم پرداخت. اما حتی بیشتر الگوهای طراحی نیز بر دو اصل پایهای شیءگرایی متکی هستند: ترکیب (Composition) و ارثبری (Inheritance). از آنجا که ترکیب سادهتر است، ابتدا از آن شروع میکنیم.
ترکیب عمل گردآوردن چند شیء با هم برای ایجاد یک شیء جدید است. ترکیب معمولاً زمانی انتخاب مناسبی است که یک شیء بخشی از شیء دیگر باشد. ما پیشتر اولین نشانههای ترکیب را هنگام صحبت دربارهٔ خودروها دیدیم. یک خودروی سوخت فسیلی از موتور، جعبهدنده (transmission)، استارت، چراغهای جلو و شیشهٔ جلو ــ در کنار بسیاری اجزای دیگر ــ ترکیب شده است. خودِ موتور نیز از پیستونها، میللنگ و سوپاپها تشکیل شده است.
در این مثال، ترکیب روشی مناسب برای ایجاد سطوح انتزاع فراهم میکند. شیء Car (خودرو) میتواند رابطی را ارائه کند که راننده به آن نیاز دارد، در حالی که همزمان دسترسی به اجزای تشکیلدهندهاش نیز وجود دارد؛ سطحی عمیقتر از انتزاع که برای مکانیک مناسب است. این اجزا نیز میتوانند در صورت نیاز مکانیک به اطلاعات بیشتر (مثلاً برای عیبیابی یا تنظیم موتور)، بیشتر به جزئیات شکسته شوند.
ماشین یک مثال رایج مقدماتی برای ترکیب است، اما در طراحی سیستمهای رایانهای چندان مفید نیست. اشیای فیزیکی را میتوان بهسادگی به اجزای کوچکتر تقسیم کرد. انسانها این کار را حداقل از زمان یونان باستان انجام دادهاند، زمانی که نظریهپردازان یونانی مطرح کردند که «اتمها» کوچکترین واحدهای ماده هستند (البته آنها به شتابدهندههای ذرات دسترسی نداشتند!).
اما از آنجا که سیستمهای رایانهای شامل مفاهیم خاص و پیچیدهاند، شناسایی اشیای تشکیلدهندهٔ آنها بهطور طبیعی مانند پیستونها و سوپاپهای دنیای واقعی اتفاق نمیافتد.
صفحه [13]
اشیای موجود در یک سیستم شیءگرا گاهی نمایانگر اشیای فیزیکی مانند افراد، کتابها یا تلفنها هستند. با این حال، در بیشتر مواقع آنها مفاهیم را نمایش میدهند. افراد نام دارند، کتابها عنوان دارند، و تلفنها برای برقراری تماس استفاده میشوند. تماسها، عنوانها، حسابها، نامها، قرار ملاقاتها و پرداختها معمولاً در دنیای فیزیکی بهعنوان «شیء» در نظر گرفته نمیشوند، اما همگی اجزایی هستند که بهطور مکرر در سیستمهای رایانهای مدلسازی میشوند.
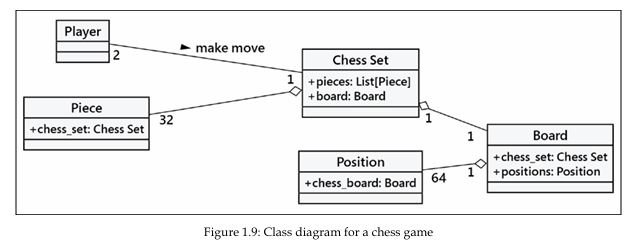
بیایید یک مثال بیشتر رایانهمحور را مدلسازی کنیم تا ترکیب (composition) را در عمل ببینیم. در اینجا طراحی یک بازی شطرنج رایانهای را بررسی میکنیم. این سرگرمی در دههٔ ۸۰ و ۹۰ میلادی بسیار محبوب بود. در آن زمان پیشبینی میشد که روزی رایانهها بتوانند یک استاد شطرنج انسانی را شکست دهند. این اتفاق در سال ۱۹۹۷ رخ داد، زمانی که Deep Blue متعلق به IBM توانست قهرمان جهان، گری کاسپاروف، را شکست دهد. پس از آن، علاقهٔ پژوهشی به مسئلهٔ شطرنج کاهش یافت. امروزه، فرزندان Deep Blue تقریباً همیشه پیروز میشوند.
یک بازی شطرنج بین دو بازیکن انجام میشود که از یک مجموعهٔ شطرنج (chess set) شامل یک صفحه (board) با ۶۴ خانه در یک شبکهٔ ۸×۸ استفاده میکنند. این صفحه میتواند دو مجموعه از ۱۶ مهره داشته باشد که در نوبتهای متناوب توسط دو بازیکن به روشهای مختلف حرکت داده میشوند. هر مهره میتواند مهرههای دیگر را بگیرد. صفحه باید بعد از هر حرکت خودش را روی صفحهٔ نمایش رایانه بازسازی (render) کند.
در این توصیف، من برخی از اشیای بالقوه را با ایتالیک و چند متد کلیدی را با بولد مشخص کردهام. این یک گام نخست رایج برای تبدیل تحلیل شیءگرا به یک طراحی است. در این نقطه، برای تأکید بر ترکیب، روی صفحهٔ شطرنج (board) تمرکز میکنیم، بدون اینکه فعلاً بیش از حد درگیر بازیکنان یا انواع مختلف مهرهها شویم.
بیایید از بالاترین سطح انتزاع ممکن شروع کنیم: ما دو بازیکن داریم که با یک Chess Set تعامل میکنند، به این صورت که نوبتی حرکت انجام میدهند:
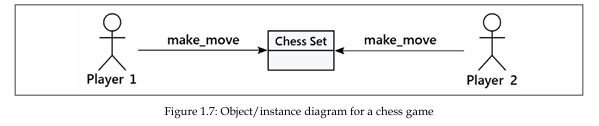
این نمودار چندان شبیه نمودارهای کلاسی قبلی ما نیست ــ و این نکته خوبی است، زیرا اصلاً قرار نیست یکی از آنها باشد! این نمودار شیء (Object Diagram) یا همان نمودار نمونه (Instance Diagram) است. این نوع نمودار سیستم را در یک وضعیت مشخص از زمان توصیف میکند و نمونههای خاصی از اشیا را نمایش میدهد، نه تعامل بین کلاسها.
به خاطر داشته باشید که هر دو بازیکن عضو یک کلاس هستند، بنابراین نمودار کلاس (Class Diagram) آن کمی متفاوت به نظر خواهد رسید:
صفحه [14]

این نمودار نشان میدهد که دقیقاً دو بازیکن میتوانند با یک مجموعهٔ شطرنج تعامل داشته باشند. همچنین نشان میدهد که هر بازیکن در هر لحظه فقط میتواند با یک Chess Set بازی کند.
با این حال، ما در حال بحث دربارهٔ ترکیب (Composition) هستیم، نه UML؛ بنابراین بیایید فکر کنیم Chess Set از چه اجزایی ترکیب شده است. در این مقطع، برایمان مهم نیست که بازیکن از چه اجزایی تشکیل شده است. میتوانیم فرض کنیم بازیکن قلب و مغز و سایر اعضا دارد، اما اینها برای مدل ما نامرتبطاند. در واقع هیچ مانعی وجود ندارد که همان بازیکن، خودِ Deep Blue باشد که نه قلب دارد و نه مغز.
پس مجموعهٔ شطرنج از یک صفحه (board) و ۳۲ مهره تشکیل شده است. خودِ صفحه نیز از ۶۴ خانه (position) تشکیل میشود. شاید استدلال کنید که مهرهها بخشی از خودِ مجموعهٔ شطرنج نیستند، چون میتوانید مهرههای یک مجموعه را با مجموعهٔ دیگری عوض کنید. هرچند در نسخهٔ رایانهای شطرنج چنین چیزی بعید یا ناممکن است، اما این بحث ما را با مفهوم تجمیع (Aggregation) آشنا میکند.
تجمیع (Aggregation) تقریباً دقیقاً شبیه ترکیب است. تفاوت در اینجاست که اشیای تجمیعی میتوانند بهطور مستقل وجود داشته باشند. برای یک خانه (position) امکانپذیر نیست که به یک صفحهٔ شطرنجِ دیگر وابسته شود؛ پس میگوییم صفحه از خانهها ترکیب شده است. اما مهرهها که ممکن است مستقل از مجموعهٔ شطرنج نیز وجود داشته باشند، گفته میشود با آن مجموعه در یک رابطهٔ تجمیعی قرار دارند.
راه دیگر برای تمایز بین تجمیع و ترکیب این است که دربارهٔ طول عمر شیء فکر کنیم:
همچنین به یاد داشته باشید که ترکیب، نوعی تجمیع است؛ تجمیع صرفاً شکل عامتری از ترکیب است. هر رابطهٔ ترکیبی یک رابطهٔ تجمیعی هم هست، اما برعکس آن همیشه صادق نیست.
بیایید ترکیب فعلی Chess Set خود را توصیف کنیم و چند ویژگی (attribute) به اشیا اضافه کنیم تا روابط ترکیبی را در خود نگه دارند: